Faster Release Cycles with Architecture Optimization [Video]
Faster Release Cycles with Architecture Optimization [Video]
CodeLogic VP of Product, Eric Minick, presented at the devops.com TechStrong Con Virtual Summit.
In this session, Eric talks about how the continuous delivery developers typically do is tied into the kinds of architectures they’re using, and how the interplay between architecture and DevOps can determine how quickly teams can deliver.
Watch the full session here, or read his article below:
Delivery at the Speed of Architecture
Hello. I’m Eric Minick, and I’m excited to talk about the interplay between architecture and DevOps and how quickly you can actually go. I’ve spent the last 15 years in the continuous integration and continuous delivery space working on various tools there.
What’s struck me over the last few years was how closely the type of continuous delivery you do is tied to the types of architectures you’re using. Things are a bit different in cloud-native than they are in distributed systems and mainframe. I’ve seen many people struggle when they’re trying to apply techniques that come from a different world to their own space. It just doesn’t fit right. I’m going to discuss how these things intersect and how to apply this knowledge within your own context.
Cloud Native, Mainframe DevOps, and Agile
As I was thinking about DevOps and architecture, I was Googling “where do you start?”. The hot topic right now is really in the cloud-native arena. The App Dynamics team talk about all sorts of best practices. On their webpage about cloud native architecture, they write,
“Cloud-native architecture is a design methodology that utilizes cloud services…to allow dynamic and agile application development techniques.”
In other words, why are they doing cloud-native? Because they want to go faster, and want to realize the benefits of Agile. I thought this statement was interesting and it points to the type of intersection I’m here to discuss.
I then thought, well, what would be the most different way of architecting than cloud-native? Alright, maybe mainframe. As I was thinking about that (“searched it up,” as my kids say), you see everybody talking about mainframe DevOps. All of the vendors in the mainframe area, whether it’s the IBMs, Broadcoms, Microfocus, BMCs, they’re all talking mainframe DevOps. Is that going to be the same cloud-native work you’re doing? Probably not. It supports Agile, and it is more similar than you might expect.
For example:
Can I set up a Jenkins pipeline to build and deploy and kick-off tests around my mainframe code?
Yes, absolutely!
Are all the same approaches going to be applicable?
No.
Be Loosely Coupled
We know that DevOps is applicable just about everywhere, but when thinking about capabilities, we must be sure to do so with the architecture that we’re actually using squarely in mind. But if it’s applicable everywhere, what are the key tenets?
I went back to one of my favorite books about DevOps, Accelerate by Forsgren, Humble, and Gene Kim. Right at the top of the section on architecture, there’s a beautiful little statement,
“High performance is possible with all kinds of systems, provided that they are loosely coupled.”
You can be successful in a DevOps fashion, measured by things like:
- How often are you delivering?
- What kind of incidents do you experience when you deliver?
- How successful is the team?
Whether you’re cloud-native, distributed, mainframe, doing IoT applications, you can achieve high performance. Whatever your fundamental architectures are, you can be successful. The key is to be loosely coupled.
The Most Important Factor for DevOps Techniques
How to think about things is not so much about the infrastructure side. While running on a big box on your data center vs. in the cloud is important, the coupling is the most important factor of success with most DevOps techniques.
If I’m writing a decoupled microservice and I think about what it takes to build, deploy and test it in order to get it out the door, it’s relatively simple. I am putting out some sort of a contract that outlines the API I’m going to fulfill, and I can then test that contract on my one service. So, I build my service, I deploy my service into a test environment, I then test that API (API tests are pretty quick). If that passes, I know I’m fulfilling my contract, as I should be, and it can then be released into production fairly independently, knowing that I’m unlikely to break anything else as long as I stick to my contract.
The same thing is true if I’m writing some mainframe app, or a service running behind some broker. If there’s an API I’m supposed to fulfill, and we test that API, I can then go out independently. If instead, I have what seems to be the most common architecture in the enterprise right now – the distributed monolith, where I have a lot of runtime services and databases – I’ll be worried that I’m going to break something else when I change one.
Even Contracts Require Coordination
We don’t all have firm contracts that we stick to, and it’s expected that people and teams have code to call from each other. If we have a distributed monolith, well, when I change my part, I’ll worry about whether other parts will break. I’ll need to deploy my part into an integration environment, get it tested, and see if it’s still working and if I’ve broken anything else. That requires coordination around testing and shared environments, and my changes are likely being tested against somebody else’s changes.
When my organization deploys to production, we’re likely not deploying just my service – we’re probably deploying lots of things together. This means the level of coordination goes up, the coordination of testing increases, and security testing gets more complicated.
In other words, everything is slower and worse.
Coupling is Better than Nice
Coupling is the architectural construct that we really care about. Running on a cloud is nice, from this perspective, and has the most impact as we look at resiliency.
If my app falls over can I bring it back really quickly?
Can I scale up and scale down nicely?
Clouds can have important impacts there. But when it comes to speed,
- How quickly do I deploy?
- How quickly do I test?
- How quickly can I release?
Loose coupling is where it’s at.
This is a principle that I’ve sort of understood in application architecture in the past, but it’s even more important today as we think about DevOps.
Architecture Mirrors Teams
I will admit, it’s not only systems that need to be loosely coupled, it’s also teams. This makes a lot of sense to anyone who’s familiar with Conway’s Law. Melvin Conway laid this down back in the 60s saying, “Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.”
This statement was simplified nicely by Eric Raymond who said, “If you have 4 development teams and you ask them to write a compiler, you’re going to get a 4 pass compiler.”
The architectures you end up with, end up being a mirror of your organization. How the different parts of your architecture interact mirrors how your organization’s people and teams interact.
This is pretty profound. You’re unlikely to get a microservices architecture if you have a single team of 100 developers with some architects and testers rolled in. With that many people involved, you’re more likely going to get a big ball of interrelated stuff because your organization structure is a big ball.
If instead, your organization is split into teams of 4-8, and those teams are kept somewhat apart from one another, then you are much more likely to get smaller services that are somewhat apart from one another. You just have to make sure that the communication between those teams is good, and that agreements and understandings are team-to-team, rather than at a low level where you’re likely to circumvent APIs.
The Inverse Conway Maneuver
This leads to a concept called The Inverse Conway Maneuver. If you want to change your architecture, change the org chart. If your org chart is not conducive to the architecture you want, change the org chart as if you’re trying to change the architecture.
If you look at what happened at Amazon as they moved to microservices, they started talking about “two pizzas” around the same time. Change the org chart to have that “two pizza” team if you want two pizzas’ worth of services.
Framing the Big Picture
With that said, here’s a look at a detailed interaction. This visualization is inspired by something I found in the Lean Enterprise book by Jez Humble. It’s credited to Paul Hammit. I’ve changed it a bit, but Paul deserves a ton of credit for creating a favorite graphic that I’ve seen in other DevOps and Lean books.
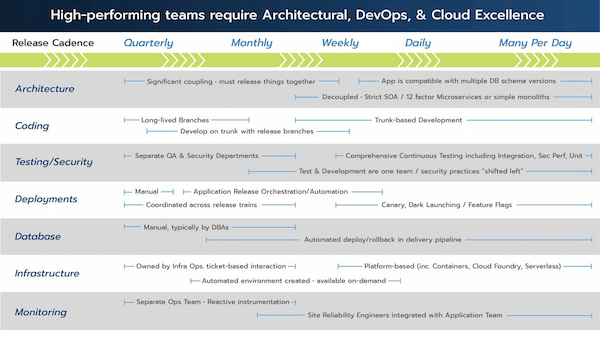
As a framing mechanism, let’s say we’ve looked at your release cadence and we’re going to map that back to different DevOps practices. If you have something like feature flags, that can be extremely powerful if you’re releasing many times a day, or daily, and if you’re going to push a release out before the functionality goes live – to toggle things on and off. That makes sense in that world.
If you’re releasing quarterly, feature flags are going to be a lot less valuable to you. So, when you read that blog entry that says, “Feature flags are how we manage to be successful in our DevOps digital transformation,” you don’t want to rush to feature flags before you bring your release cadence faster than quarterly. Get it to weekly, at least.
Mapping Your Practices to Speed
Next, we’re going to map practices to speed. I’ll infer that this is roughly a logarithmic type of visualization, e.g. many times a day is 10 or 20x faster than daily, the same way that weekly is 4 or 5x faster than monthly. It’s logarithmic as we work our way across.
Starting on the left hand side of this graph, I’m looking at how things work both in that quarter and monthly, and kind of getting into weekly. I want to do that because a lot of these practices are put into ranges where they are actually ineffective. They stop being effective somewhere around the twice monthly release/ every 2-week release cadence.
Moving from a monthly cadence to a weekly cadence is bigger than moving from a quarterly to monthly cadence. A lot of practices break in this cycle, so if you found that you were able to go from quarterly to monthly well, and started struggling as you went to every two weeks and don’t really get to weekly, that’s pretty normal, because that’s where things tend to break.
Crediting Cadence
From an architectural point of view, you can have significant coupling. You can have a distributed monolith and be okay down to maybe a weekly release, even bi-weekly release. Testing a bunch of things together and releasing a bunch of things together can be accommodated pretty well.
Before joining CodeLogic to focus on architecture, I worked on release automation tools to take a bunch of related stuff and move it through a pipeline together. These kinds of release-automation tools will get you from a monthly release to a bi-weekly or weekly release with coupling. A lot of what you’d do in a bi-weekly release can look like what you’re doing in a quarterly release cycle, just better: More automation, faster sprints, and better accuracy.
From a coding perspective, how you approach your day-to-day development and branching structure can have long-lived branches. You may have a release branch for the next release, up to about a monthly release, and you might have release branches that you keep around for a bi-weekly or weekly release. You will see that it doesn’t make sense to have branches for longer releases as you get faster than a weekly release, they just don’t live long enough to be worth the overhead.
QA Testing the Waters
From a testing point of view, you’re going to need increased automation as you move from a quarterly release down to that bi-weekly release. You’ll need to be most automated for bi-weekly releases, but that automation can be done with a blend of development and a dedicated QA team.
If you’re releasing once a month or twice a month, you have to have time for meetings with QA. Your databases will benefit as you get into bi-weekly or weekly releases if you automate your database deployments, just like you did your app deployments. If you’re not updating your databases all the time, you can still get away with manual database updates up to about a bi-weekly release. After that, you’ll really want to automate it.
Creating Your Environment
From an infrastructure point of view, as fun as it is to get a test environment, or do an automated test from spinning up a test environment, you can also have VMs that are your test environment. When you do builds, chuck them out there, run some automated tests, maybe even some manual tests.
For the traditional VM environment, where if you needed a new environment you’d create a ticket in ServiceNow and ask someone to please create you a new environment that you’d get it in a couple weeks, this is probably okay as long as you don’t need different environments for every release (which you usually don’t). Traditional infrastructure can typically do okay – you don’t need cloud.
From a monitoring point of view, again, a fairly traditional set up with an operational team that keeps an eye on when things go sideways. As you accelerate you’ll have more and more changes going into production. You’ll need better monitoring, ideally more proactive monitoring that can identify smoke not fire. APM tools these days are pretty good at that sort of thing. Organizationally, you don’t need to change everything for a monthly release or bi-weekly release. But as you accelerate, things are going to be a little bit different.
Beyond Bi-Weekly
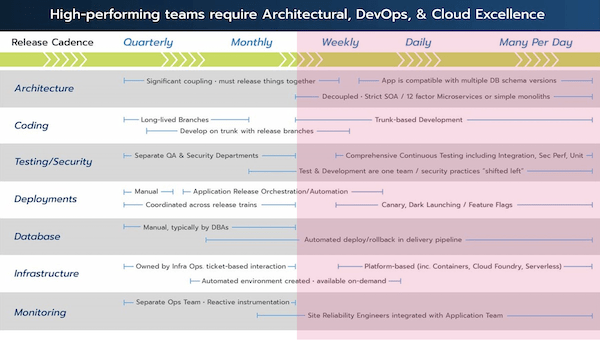
Looking to the right side of this graph, as you start getting past a bi-weekly release, you won’t have the time for coordination. This is where that decoupled microservice is important. Strict service-oriented architecture is another way to look at this. When we talked about service-oriented architectures 10-15 years ago, it was the same idea as microservices in many ways: we just want to decouple things in order to have smaller, isolated chunks responsible for distinct activities and domains. You can still have that enterprise service bus, that’s fine, if you’re actually decoupled.
Most of us had massively coupled distributed monoliths with the need for speed in the middle of it. Now we’re trying to get away from that. That decoupling needs to take into account the database tier. There’s a lot of good content around how you would align the data to those individual services and put in some event messaging systems. All of that comes in. This can be a profound re-architecture to move from a distributed monolith to an actual decoupled service that can accommodate data change.
Re-Architecture: A Big Lift
Re-architecture is a big lift. A key consideration in deciding whether or not to make that lift is knowing whether you need these kinds of capabilities – or whether they’re just nice to have. If you can get to pretty good uptime, adequate scalability and a bi-weekly release cycle, is that good enough for the business or do you need to make that bigger investment to transform to something else going forward?
As you go forward, you can make these sorts of changes. A lot of the things you do will also change, but are in many ways simpler. The branching strategy and coding methods are good examples of this. You’ll move from managing lots of different branches and dealing with merge flows, to something that looks a lot more like trunk-based development that has a GitFlow element to it. You shouldn’t have pull requests and merge requests sitting out by themselves for a long time – they need to be pulled in fairly quickly.
Automation = Good
From a testing point of view, you need really good test automation at this point. You’re not doing a lot of manual testing. This probably means your testers and developers are one team, working together. Your deployments are a lot simpler and you’re not doing things fancy because you’re coordinating lots of things going out together. You’re going to reserve your fanciness for a progressive-delivery-style of change.
How do you deploy something and test it in production with customer usage, rather than just rely on those functional tests or automated unit tests you ran earlier? Those feature flags become absolutely critical. You’ll want to adopt techniques that allow you to release your software or features of your software to a subset of your users, whether that’s Canary or Dark Launch, or something similar.
Also: databases. Not only does the architecture needs to be tidy, but also how you do your deployments of that database. You’re not doing handcrafted SQL deployments anymore. You need some system in place to automate your database change. Maybe you’re doing something with a DBMaestro or Liquidbase – some way of automating to make sure your database changes are as seamless as your application tier. That will change a bit whether you’re doing SQL or NoSQL-style database changes.
Environments on Demand
From an infrastructure point of view, you need to be able to get the environments that you want more or less on-demand. Saying that you’re going to microservices and then be in a situation where you need to create a bunch of tickets and beg the infrastructure team for more infrastructure in order to run the next service will discourage you from having the architecture that you want.
You should have a platform. There’s been an increase in platform teams in the industry that make sure platforms are available to the application teams – possibly Kubernetes-based or serverless. Whatever that platform is, you need a simple way of getting your infrastructure to match your new capabilities.
Monitoring in Proactive-Mode
Finally, monitoring. You’re likely moving into a much more proactive mode than you were before. The relationship between the operations team monitoring the app to see if it falls over, and the development team, must be much tighter. You might be in a “you build it, you run it” kind of mode where the development team is the operations team or the operations team is within it.
Or, you might have something more like a Site Reliability Engineer, which spans the traditional, more modern approach and brings dedicated expertise in, while still putting responsibility back on development. There’s some flexibility there, but the old ways of working are just not going to cut it.
This is a summary that I could very easily spend way more time on, and hopefully, it makes sense. You want to be able to draw a vertical line where your desired release cadence is, look at the practices there, compare that to the actual practices you have, and say, “Yeah, that’s about what we’re doing. We are in the right realm.”
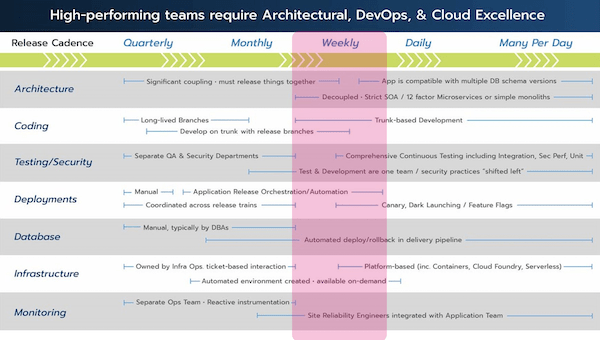
When you start doing things on the right, while your release cadence and other things you’re doing are way off on the left, you’ll get a mess that can spell trouble quickly. Again, I want to point out that somewhere between monthly and weekly, a ton of things change.
So, if you’re looking to make that leap, expect that you need to change everything: how you’re doing deployments, tests, and managing your databases and [potentially] your infrastructure.
Your architecture better be as decoupled as that senior architect said it was up on the whiteboard.
That’s my challenge for you, should you choose to accept!
Key Takeaways:
- Your architecture constrains your release cadence. If you’re not decoupled, don’t try to go faster than once a week.
- Re-architecting is really expensive. If you’re going to make the leap, it should be because you have a resiliency issue, or you need to go faster than once a week on your releases. Don’t re-architect just for fun. If you do have to rewrite an app, architect it as best as you can.
- Align your organization and keep Conway’s Law in mind. Make sure the organization, practices and architecture are all in line.
And with that, I’ll wrap up. Thank you and cheers!